Admissible decision rule
In statistical decision theory, an admissible decision rule is a rule for making a decision such that there isn't any other rule that is always "better" than it, in a specific sense defined below.
Generally speaking, in most decision problems the set of admissible rules is large, even infinite, so this is not a sufficient criterion to pin down a single rule, but as will be seen there are some good reasons to favor admissible rules; compare Pareto efficiency.
Contents |
Definition
Define sets 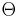 ,
, 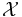 and
and 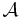 , where are the states of nature, the possible observations, and the actions that may be taken. An observation
, where are the states of nature, the possible observations, and the actions that may be taken. An observation 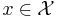 is distributed as
is distributed as 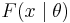 and therefore provides evidence about the state of nature
and therefore provides evidence about the state of nature 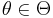 . A decision rule is a function
. A decision rule is a function 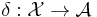 , where upon observing
, where upon observing 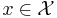 , we choose to take action
, we choose to take action 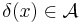 .
.
Also define a loss function 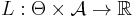 , which specifies the loss we would incur by taking action
, which specifies the loss we would incur by taking action 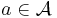 when the true state of nature is
when the true state of nature is 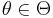 . Usually we will take this action after observing data , so that the loss will be
. Usually we will take this action after observing data , so that the loss will be 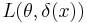 . (It is possible though unconventional to recast the following definitions in terms of a utility function, which is the negative of the loss.)
. (It is possible though unconventional to recast the following definitions in terms of a utility function, which is the negative of the loss.)
Define the risk function as the expectation
![R(\theta,\delta)=\operatorname{E}_{F(x\mid\theta)}[{L(\theta,\delta(x))]}.\,\!](/2012-wikipedia_en_all_nopic_01_2012/I/0adcf1fd4491c3d25b53721dca2b8a2c.png)
Whether a decision rule 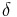 has low risk depends on the true state of nature
has low risk depends on the true state of nature 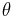 . A decision rule
. A decision rule 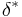 dominates a decision rule if and only if
dominates a decision rule if and only if 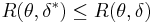 for all , and the inequality is strict for some .
for all , and the inequality is strict for some .
A decision rule is admissible (with respect to the loss function) if and only if no other rule dominates it; otherwise it is inadmissible. Thus an admissible decision rule is a maximal element with respect to the above partial order. An inadmissible rule is not preferred (except for reasons of simplicity or computational efficiency), since by definition there is some other rule that will achieve equal or lower risk for all . But just because a rule is admissible does not mean it is a good rule to use. Being admissible means there is no other single rule that is always better - but other admissible rules might achieve lower risk for most that occur in practice. (The Bayes risk discussed below is a way of explicitly considering which occur in practice.)
Bayes rules and generalized Bayes rules
Bayes rules
Let 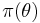 be a probability distribution on the states of nature. From a Bayesian point of view, we would regard it as a prior distribution. That is, it is our believed probability distribution on the states of nature, prior to observing data. For a frequentist, it is merely a function on
be a probability distribution on the states of nature. From a Bayesian point of view, we would regard it as a prior distribution. That is, it is our believed probability distribution on the states of nature, prior to observing data. For a frequentist, it is merely a function on 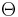 with no such special interpretation. The Bayes risk of the decision rule with respect to is the expectation
with no such special interpretation. The Bayes risk of the decision rule with respect to is the expectation
![r(\pi,\delta)=\operatorname{E}_{\pi(\theta)}[R(\theta,\delta)].\,\!](/2012-wikipedia_en_all_nopic_01_2012/I/9d0d47a9fce71882c07838759d386657.png)
A decision rule that minimizes 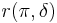 is called a Bayes rule with respect to . There may be more than one such Bayes rule. If the Bayes risk is infinite for all , then no Bayes rule is defined.
is called a Bayes rule with respect to . There may be more than one such Bayes rule. If the Bayes risk is infinite for all , then no Bayes rule is defined.
Generalized Bayes rules
In the Bayesian approach to decision theory, the observed 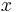 is considered fixed. Whereas the frequentist approach (i.e., risk) averages over possible samples , the Bayesian would fix the observed sample and average over hypotheses . Thus, the Bayesian approach is to consider for our observed the expected loss
is considered fixed. Whereas the frequentist approach (i.e., risk) averages over possible samples , the Bayesian would fix the observed sample and average over hypotheses . Thus, the Bayesian approach is to consider for our observed the expected loss
![\rho(\pi,\delta \mid x)=\operatorname{E}_{\pi(\theta \mid x)} [ L(\theta,\delta(x)) ]. \,\!](/2012-wikipedia_en_all_nopic_01_2012/I/5d768e280611b875cf24d674e86aa7e4.png)
where the expectation is over the posterior of given (obtained from and using Bayes' theorem).
Having made explicit the expected loss for each given separately, we can define a decision rule by specifying for each an action 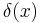 that minimizes the expected loss. This is known as a generalized Bayes rule with respect to . There may be more than one generalized Bayes rule, since there may be multiple choices of that achieve the same expected loss.
that minimizes the expected loss. This is known as a generalized Bayes rule with respect to . There may be more than one generalized Bayes rule, since there may be multiple choices of that achieve the same expected loss.
At first, this may appear rather different from the Bayes rule approach of the previous section, not a generalization. However, notice that the Bayes risk already averages over in Bayesian fashion, and the Bayes risk may be recovered as the expectation over of the expected loss (where 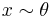 and
and 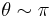 ). Roughly speaking, minimizes this expectation of expected loss (i.e., is a Bayes rule) iff it minimizes the expected loss for each separately (i.e., is a generalized Bayes rule).
). Roughly speaking, minimizes this expectation of expected loss (i.e., is a Bayes rule) iff it minimizes the expected loss for each separately (i.e., is a generalized Bayes rule).
Then why is the notion of generalized Bayes rule an improvement? It is indeed equivalent to the notion of Bayes rule when a Bayes rule exists and all have positive probability. However, no Bayes rule exists if the Bayes risk is infinite (for all ). In this case it is still useful to define a generalized Bayes rule , which at least chooses a minimum-expected-loss action 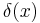 for those for which a finite-expected-loss action does exist. In addition, a generalized Bayes rule may be desirable because it must choose a minimum-expected-loss action for every , whereas a Bayes rule would be allowed to deviate from this policy on a set
for those for which a finite-expected-loss action does exist. In addition, a generalized Bayes rule may be desirable because it must choose a minimum-expected-loss action for every , whereas a Bayes rule would be allowed to deviate from this policy on a set 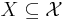 of measure 0 without affecting the Bayes risk.
of measure 0 without affecting the Bayes risk.
More important, it is sometimes convenient to use an improper prior . In this case, the Bayes risk is not even well-defined, nor is there any well-defined distribution over . However, the posterior 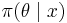 -- and hence the expected loss—may be well-defined for each , so that it is still possible to define a generalized Bayes rule.
-- and hence the expected loss—may be well-defined for each , so that it is still possible to define a generalized Bayes rule.
Admissibility of (generalized) Bayes rules
According to the complete class theorems, under mild conditions every admissible rule is a (generalized) Bayes rule (with respect to some prior -- possibly an improper one—that favors distributions where that rule achieves low risk). Thus, in frequentist decision theory it is sufficient to consider only (generalized) Bayes rules.
Conversely, while Bayes rules with respect to proper priors are virtually always admissible, generalized Bayes rules corresponding to improper priors need not yield admissible procedures. Stein's example is one such famous situation.
Examples
The James–Stein estimator is a nonlinear estimator which can be shown to dominate, or outperform, the "ordinary" (least squares) technique with respect to a mean-square error loss function.[1] Thus least squares estimation is not necessarily an admissible estimation procedure. Some others of the standard estimates associated with the normal distribution are also inadmissible: for example, the sample estimate of the variance when the population mean and variance are unknown.[2]
See also
Notes
- ^ Cox & Hinkley 1974, Section 11.8
- ^ Cox & Hinkley 1974, Exercise 11.7
References
- Cox, D.R.; Hinkley, D.V. (1974). Theoretical Statistics. Wiley. ISBN 0-412-12420-3.
- Berger, James O. (1980). Statistical Decision Theory and Bayesian Analysis (2nd ed.). Springer-Verlag. ISBN 0-387-96098-8.
- DeGroot, Morris (2004) [1st. pub. 1970]. Optimal Statistical Decisions. Wiley Classics Library. ISBN 0-471-68029-X.
- Robert, Christian P. (1994). The Bayesian Choice. Springer-Verlag. ISBN 3-540-94296-3.